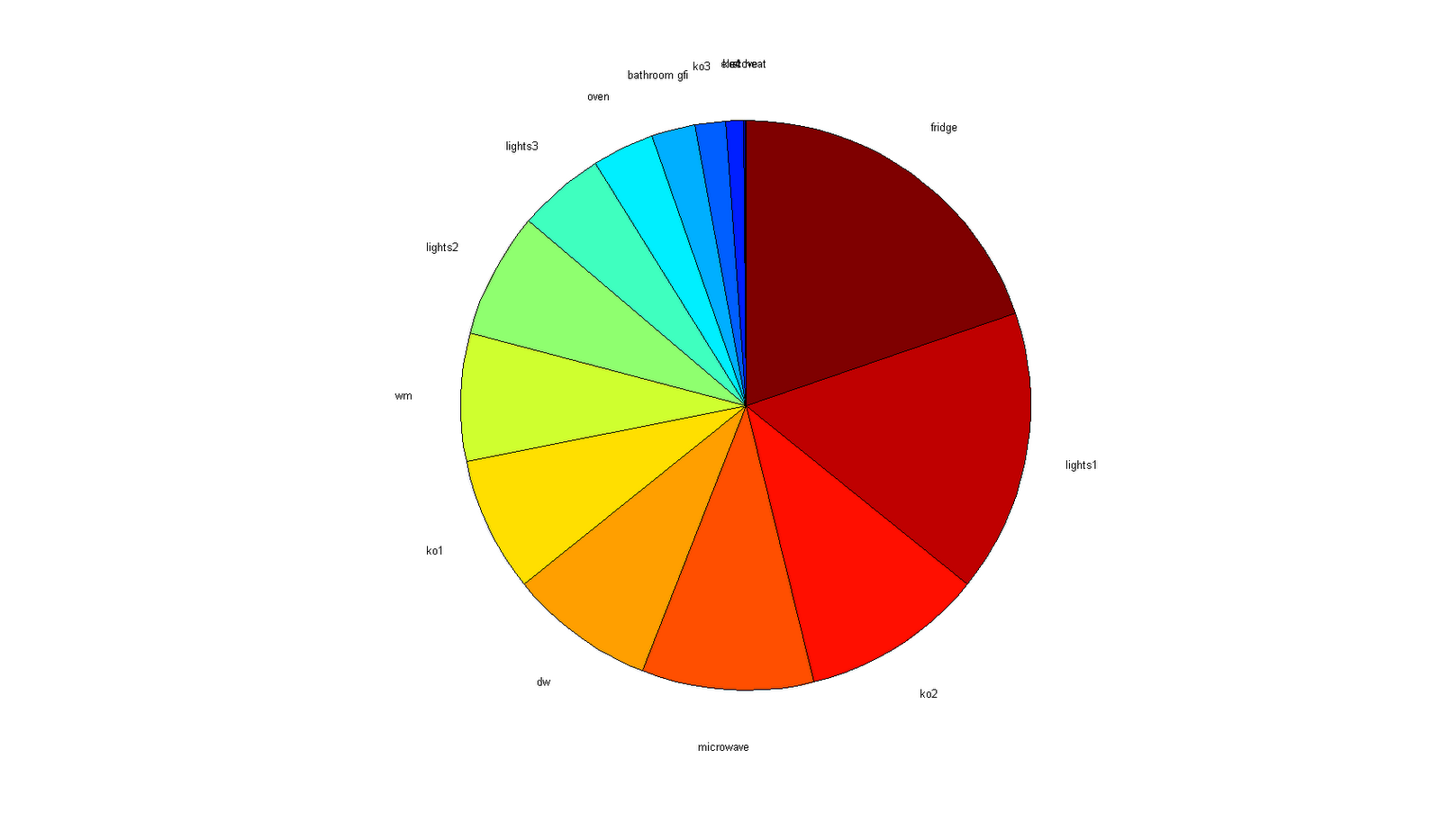
At this stage, there are three potential directions I would like to explore to improve our current model of appliances:
- Use of additional data sources (e.g. time of day, weather reports)
- Explicit modelling of appliance duration
- Steady-state analysis using hidden Markov models
Use of additional data sources
There are data sources available that could increase the accuracy of a NIALM. Examples are the unlikely use of a kettle overnight and the unlikely use of a tumble dryer when the weather is nice.
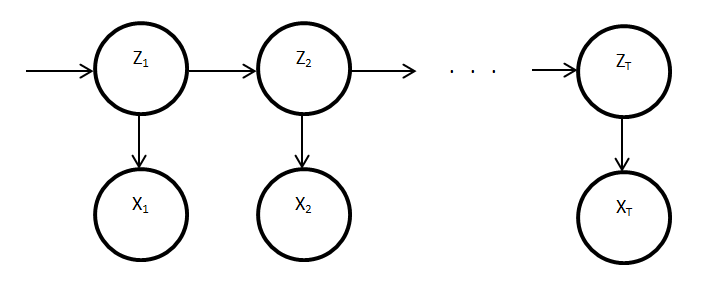
The model of appliances using HMMs can be extended to include such information. This requires the addition of a new sequence of observed variables, upon which the appliance states are conditionally dependent. This results in an input-output hidden Markov model as is shown below:
where:
- circles represent continuous variables, squares represent discrete variables
- shaded represent latent (hidden) variables, white represent observed variables
- a represents a sequence of an additional data source (e.g. time of day)
- z represents a Markov chain of appliance states
- x represents a sequence of appliance power readings
- T represents the number of time slices
By specifying the distribution of appliance states conditional upon the additional data source, the model can perform more accurate inference over appliance states without increasing the complexity of such inference. The probability of an assignment of values to the hidden variables can be calculated:
Explicit modelling of appliance duration
In the current model, the expected duration of each appliance's operation is modelled implicitly through the transition matrices. Although the transition probabilities are fixed for each time slice, they still determine the expected duration of an appliance when considering a sequence of observations. Consider an appliance with transition probabilities such that it will stay in the same state with probability 0.8 and change state with probability 0.2. We would expect the appliance to change state on average every 5 time slices, and such a sequence would be evaluated with a higher probability than one with state changes every 10 slices.
An alternative approach would be to model the probability of the next transition as conditionally dependent on the current state and its duration. The duration of the current state refers to the number of previous time slices during which the appliance's state has not changed. The graphical model stays unchanged, however the probability of an assignment of values to the hidden variables is now calculated:
where d at time slice n-1 refers to the duration of the current state.
This will complicate inference over the model, however such models have been successfully applied to many fields, including speech, human activity and hand writing recognition.
Steady-state analysis using hidden Markov models
So far we have used the sequence of power readings as the observed variables. Steady-state analysis is an alternative approach which aims to identify continuous states by the lack of change between consecutive power readings. HMMs can also be used for steady-state analysis by using the difference between consecutive power readings as the observed variable, instead of the power readings themselves. Inference over the HMM would remain the same, although the states in the HMM would no longer refer to appliance operating states. Instead, they would represent each possible transition to a new state in addition to a transition to the same state. The lattice diagram below shows the states of an HMM for steady-state analysis:

This above lattice diagram shows all the possible transitions between states. The lattice is fully connected between consecutive time slices, with the exception of consecutive turn on and turn off states. This is due to the fact that an appliance must first turn on before it can turn off and visa versa.
Each state is now responsible for a corresponding observation. For instance, the no change state would be expected to emit an observation close to 0, the turn on state might be expected to emit an observation of 50 while the turn off state would be expected to emit an observation of -50.
Conclusion
All three extension present improvements upon the existing appliance model, and should therefore lead to better appliance power disaggregation accuracy. However, I think the second method which uses semi-Markov models increases the complexity of inference for little gain in accuracy. However, the other two approaches provide significant advantages, in that the first allows predictions to be based on more data, while the second allows only a subset of appliances to be modelled. It should be possible to combine both of these two approaches, and therefore these will constitute a thorough investigation over the next few months.