About a year ago I posted a short list of some of the most useful papers for NIALM. Since then I have learnt a lot, found much more material and read many newly published papers. This post is intended as an update to the original list, containing what I now believe to be the most relevant and useful academic papers. Below is my top 10 papers for NIALM (in alphabetical order). Any comments and discussions are welcome!
- Berges ME, Goldman E, Matthews HS, Soibelman L. Enhancing Electricity Audits in Residential Buildings with Nonintrusive Load Monitoring. Journal of Industrial Ecology. 2010;14(5):844-858.
- This article provides an up-to-date overview of the practicalities of NIALM. Since many approaches require a specific monitoring device, it is useful to understand the range of hardware available and their associated costs. The authors relate the capabilities of such hardware to the potential for NIALM, including an overview of general appliance behaviour and their power demands.
- Chang H-H, Lin C-L, Lee J-K. Load identification in nonintrusive load monitoring using steady-state and turn-on transient energy algorithms. In: International Conference on Computer Supported Cooperative Work in Design.; 2010:27-32.
- This paper combines steady-state and transient-state NIALM approaches with strong classification methods from the field of machine learning. The authors use a trained neural network as the disaggregation decision engine based on the extracted features. It is clear from the paper that the use of transient energy can project previously indistinguishable inputs into unique feature space.
- Hart GW. Nonintrusive appliance load monitoring. Proceedings of the IEEE. 1992;80(12):1870-1891.
- This is the seminal work by Hart which defines the field of NIALM. The paper provides insight into the aims and applications of such technology, in addition to summarising both his own and other related work in the late 80s and early 90s. Hart explains the intuition behind many approaches to NIALM, including his 'total load model' (also known as integer programming or combinatorial optimisation) and 'appliance model' (which has since been extended using HMMs). Finally, the paper gives an unbiased evaluation of the realistic potential and limitations for the field.
- Kim H, Marwah M, Arlitt MF, Lyon G, Han J. Unsupervised Disaggregation of Low Frequency Power Measurements. In: The 11th SIAM International Conference on Data Mining. Mesa, Arizona; 2011:747-758.
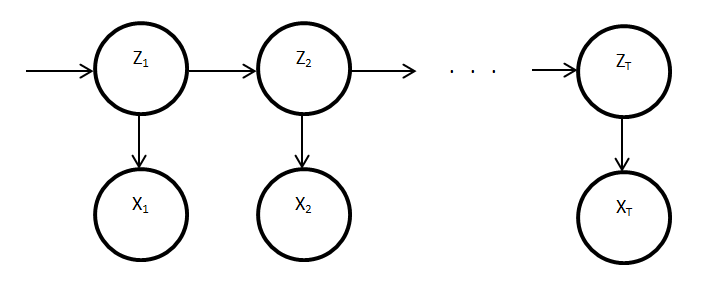
- This paper describes how Factorial HMMs (FHMM) from the machine learning domain can be used for NIALM. The authors cover the tractability of both training and inference over such models. Two extensions of the basic FHMM are described and evaluated; the use of additional data sources (e.g. time of day) and the dependencies between appliances (PC and monitor).
- Kolter JZ, Johnson MJ. REDD : A Public Data Set for Energy Disaggregation Research. In: Workshop on Data Mining Applications in Sustainability (SIGKDD). San Diego, CA; 2011:1-6.
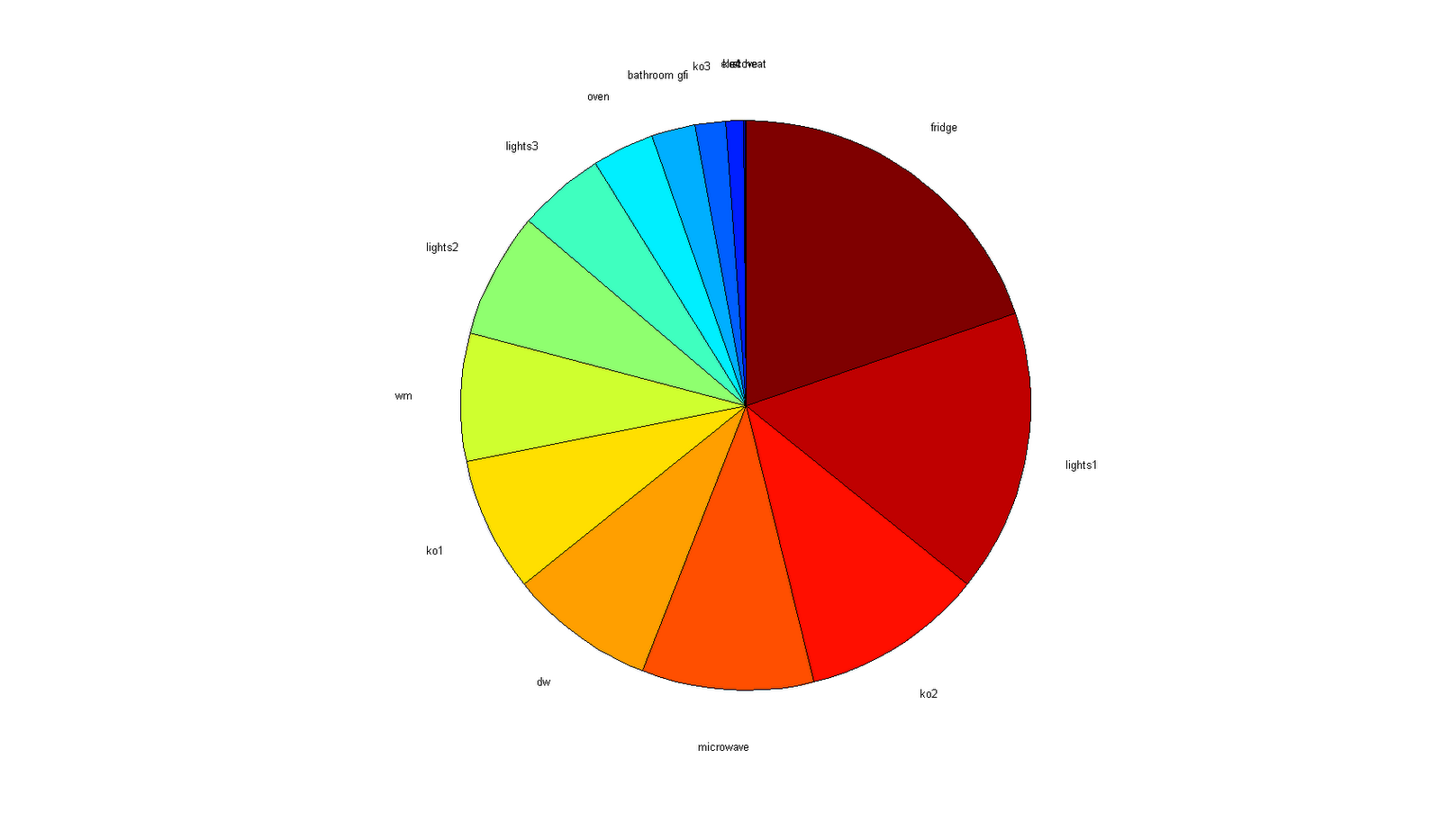
- This paper describes a recently published public data set for evaluating NIALM methods. This tackles the issue that, generally, energy disaggregation approaches are evaluated on different data sets, making direct performance comparison impossible. The data collected includes energy monitors at premises-level, circuit-level and appliance-level in 6 homes in the US. However, only premises-level data in kHz range and circuit-level data in Hz range have been realised in v1.0.
- Laughman C, Lee K, Cox R, et al. Power signature analysis. IEEE Power and Energy Magazine. 2003;1(2):56-63.
- This article provides a high level overview of the state of the art at the time of publishing. The approaches discussed include those applicable to high granularity data, such as harmonic and transient analysis, in addition to steady-state disaggregation methods. Finally, some intuition is given into how appliances with a continuously varying power draw can be disaggregated.
- Liang J, Ng S, Kendall G, Cheng J. Load Signature Study - Part I: Basic Concept, Structure, and Methodology. IEEE Transactions on Power Delivery. 2010;25(2):551-560.
- The first part of this pair of papers gives an in-depth and up-to-date discussion of the various approaches to NIALM. The authors also provide a useful description of how multiple approaches can be combined to give a single, more accurate classification. Finally, an evaluation of the many accuracy metrics which have been used is also given.
- Liang J, Ng SKK, Kendall G, Cheng JWM. Load Signature Study - Part II: Disaggregation Framework, Simulation, and Applications. IEEE Transactions on Power Delivery. 2010;25(2):561-569.
- The second part of this pair of papers gives a detailed description of a household simulator that would generate data that could be used to test NIALM algorithms. This allowed the authors to analyse the effect of many different situations, such as noise, concentration of appliance events, the impact of simultaneously operating appliances and the impact of similar appliances. The simulations confirm the first paper's proposal that the fusion of NIALM techniques can improve the disaggregation performance.
- Norford LK, Leeb SB. Non-intrusive electrical load monitoring in commercial buildings based on steady-state and transient load-detection algorithms. Energy and Buildings. 1996;24(1):51-64.
- This article gives a description of how NIALM techniques successful in domestic settings can be extended of commercial buildings. Interestingly, commercial buildings do not only present a new set of appliances, but also bring new applications to the field, such as fault detection. The authors discuss the performance of state-of-the-art steady-state and transient-state disaggregation methods at the time of publishing.
- Zeifman M, Roth K. Nonintrusive appliance load monitoring: Review and outlook. IEEE Transactions on Consumer Electronics. 2011;57(1):76-84.
- This paper is focussed entirely on giving a description and critique of all techniques applied within the NIALM field over the past 25 years. The range of approaches identified by the authors make this paper very useful when viewing the field as a whole. Accuracy metrics are also discussed, with the authors concluding that there is no agreed metric on which disaggregation performance should be assessed.