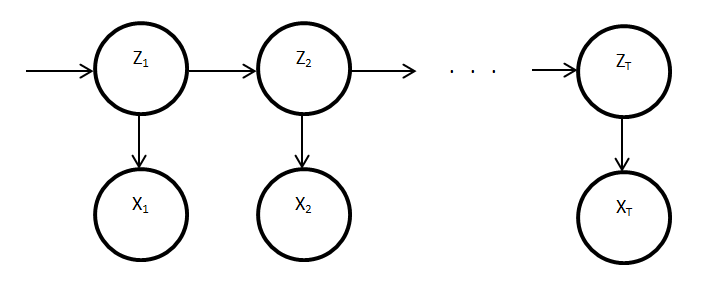
where:
- Zt - hidden (latent) variable at time t (appliance state)
- Xt - observed variable at time t (power reading)
For a given set of observed variables, we can expand the possible chains of hidden variable states as a lattice diagram:

where:
- k - appliance state
It can be seen from this diagram that the number unique chains of hidden variables through this lattice scales exponentially with the length of the chain. However, the max-sum algorithm (called the Vertibi algorithm in this case) can be used to find the probability of the most likely chain, with complexity that grows only linearly with the length of the chain. The values of the most likely chain can then be found by backtracking through the chain starting from the final time slice of the most likely chain.
The Viterbi algorithm involves calculating the joint probability of a chain of observed and hidden variables, given by:

where:
- X - set of observed variables
- Z - set of hidden variables
- theta = {pi, A, phi} - model parameters
- pi - probability density of z1
- A - appliance transition probability matrix
- phi - emission density (probability density of observed variable given a hidden variable)
- N - number of time slices
The model parameters parameters can be learnt from the set of observed variables using the Expectation-Maximisation algorithm. However, we may want to introduce a prior belief over some parameters, or even fix some parameters. For example, we might know the state of the appliance at the start of the chain, and can therefore fix pi. We might also know the parameters governing the emission density, and if we assume the observations are normally distributed we might want to fix the mean and variance parameters of the Gaussian function.
Although this model can represent appliances with more than two states, it is unclear how tractable the EM algorithm will be for a factorial hidden Markov model. One solution would be to model the multiple Markov chains as a single Markov chain, whose number of states is equal to the number of combinations of appliance states. However, the complexity of such a model is then exponential in the number of appliances. It is worth noting that we can prune the number of possible transitions based on the assumption that only one appliance can change state between two consecutive time slices, which is a practical assumption assuming a small time interval between time slices. A solution to solving this might be to use sampling methods.




















